
Analysis-Ready Cloud-Optimized Datasets¶
Overview¶
In this notebook, we will work on understanding the main concepts of creating ARCO datasets for the Geosciences.
- Analysis-Ready datasets
- Cloud-Optimized datasets
- Fair principles
- Zarr format
Prerequisites¶
| Concepts | Importance | Notes |
|---|---|---|
| Intro to Xarray | Necessary | Basic features |
| Radar Cookbook | Necessary | Radar basics |
| Intro to Zarr | Necessary | Zarr basics |
- Time to learn: 30 minutes
Imports¶
import xarray as xr
import fsspec
from glob import glob
import xradar as xd
import matplotlib.pyplot as plt
import cmweather
import numpy as np
import hvplot.xarray
from xarray.core.datatree import DataTree
from zarr.errors import ContainsGroupError Analys-Ready¶
Analysis-Ready data is a concept that emphasizes the preparation and structuring of datasets to be immediately usable for analysis. In the CrowdFlower Data Science Report 2016, the “How Data Scientists Spend Their Time” figure illustrates the distribution of time that data scientists allocate to various tasks. The figure highlights that the majority of a data scientist’s time is dedicated to preparing and cleaning data (~80%), which is often considered the most time-consuming and critical part of the data science workflow.
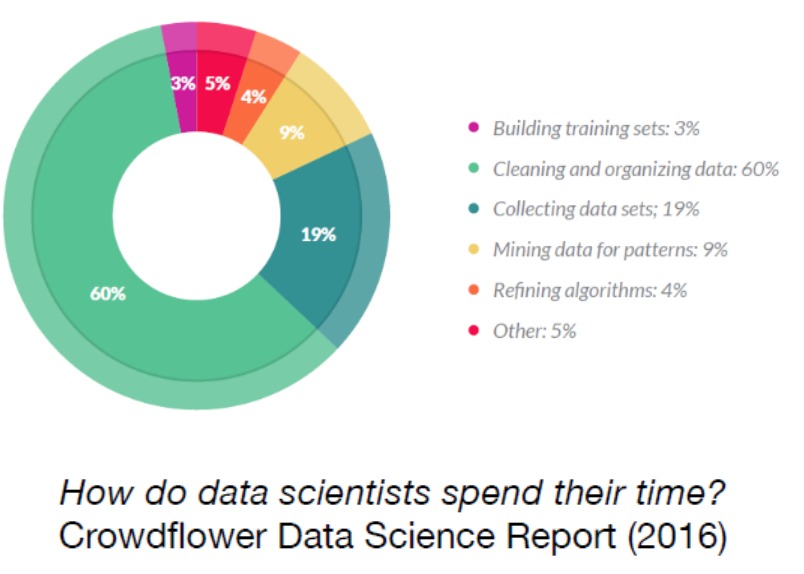
Here’s how AR caters to various aspects:
- Datasets instead of data files
- Pre-processed datasets, ensuring it is clean and well-organized
- Dataset enriched with comprehensive metadata
- Curated and cataloged
- Facilitates a more efficient and accurate analysis
- More time for fun (science)
Cloud-Optimized¶
NetCDF/Raw radar data formats are not cloud optimized. Other formats, like Zarr, aim to make accessing and reading data from the cloud fast and painless. Cloud-Optimized data is structured for efficient storage, access, and processing in cloud environments.
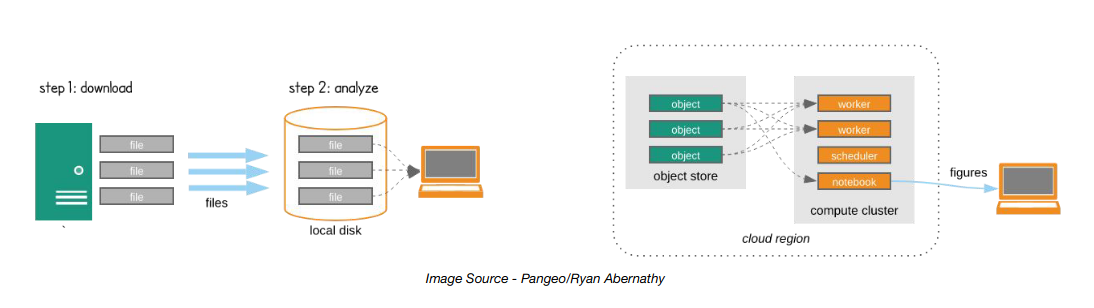
Cloud-Optimized leverages scalable formats and parallel processing capabilities
FAIR data¶
FAIR data adheres to principles that ensure it is Findable, Accessible, Interoperable, and Reusable. These guidelines promote data sharing, collaboration, and long-term usability across various platforms and disciplines.
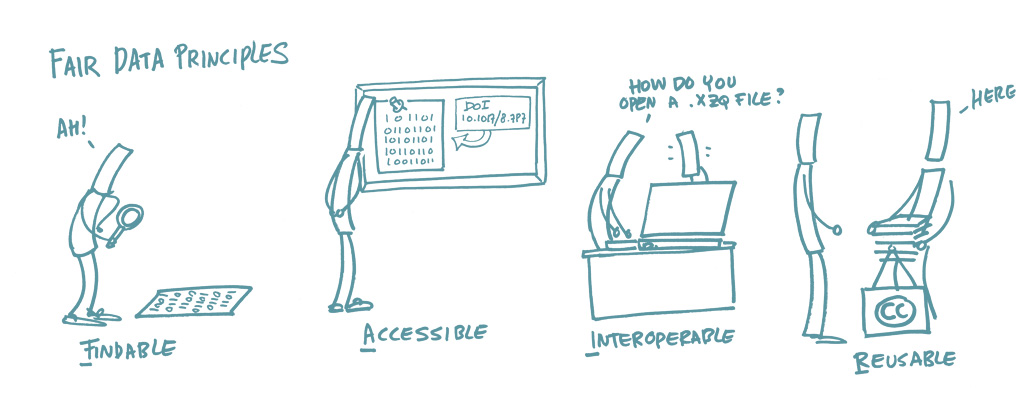
“FAIR sharing of data is beneficial for both data producers and consumers. Consumers gain access to interesting datasets that would otherwise be out of reach. Producers get citations to their work, when consumers publish their derivative work. OME-Zarr is the technology basis for enabling effective FAIR sharing of large image datasets.” Zarr illustrations
Courtesy: Zarr illustrations
Zarr format¶
Zarr is a flexible and efficient format for storing large, chunked, compressed, multi-dimensional arrays, enabling easy and scalable data access in both local and cloud environments. It supports parallel processing and is widely used in scientific computing for handling large datasets.
Courtesy: Zarr illustrations
ARCO Radar data¶
Leveraging the Climate and Forecast (CF) format-based FM301 hierarchical tree structure, endorsed by the World Meteorological Organization (WMO), and Analysis-Ready Cloud-Optimized (ARCO) formats, we developed an open data model to arrange, manage, and store radar data in cloud-storage buckets efficiently
CfRadial2.1/FM301 standard¶
Xradar employs xarray.DataTree objects to organize radar sweeps within a single hierachical structure, where each sweep is an xarray.Dataset containing relevant metadata and variables.

Let’s see how this hierarchical-datatree looks like
# Connection to Pythi s3 Bucket
URL = 'https://js2.jetstream-cloud.org:8001/'
path = f'pythia/radar/erad2024'
fs = fsspec.filesystem("s3", anon=True, client_kwargs=dict(endpoint_url=URL))
# C-band radar files
path = "pythia/radar/erad2024/20240522_MeteoSwiss_ARPA_Lombardia/Data/Cband/*.nc"
radar_files = fs.glob(path)
radar_files[:3]['pythia/radar/erad2024/20240522_MeteoSwiss_ARPA_Lombardia/Data/Cband/MonteLema_202405221300.nc',
'pythia/radar/erad2024/20240522_MeteoSwiss_ARPA_Lombardia/Data/Cband/MonteLema_202405221305.nc',
'pythia/radar/erad2024/20240522_MeteoSwiss_ARPA_Lombardia/Data/Cband/MonteLema_202405221310.nc']# open files locally
local_files = [
fsspec.open_local(
f"simplecache::{URL}{i}", s3={"anon": True}, filecache={"cache_storage": "."}
)
for i in radar_files[:5]
]We can open one of this nc files using xradar.io.open_cfradial1_datree method
dt = xd.io.open_cfradial1_datatree(local_files[0])
display(dt)Let’s create our first ARCO dataset using .to_zarr method.
dt.to_zarr("radar.zarr", consolidated=True)We can check that a new Zarr store is created (Object storage)
!ls ARCO-Datasets.ipynb QPE-QVPs.ipynb radar.zarr
This is stored locally, but could be stored in a Bucket on the cloud. Let’s open it back using Xarray.backends.api.open_datatree
dt_back = xr.backends.api.open_datatree(
"radar.zarr",
consolidated=True
)/srv/conda/envs/notebook/lib/python3.11/site-packages/xarray/backends/plugins.py:149: RuntimeWarning: 'netcdf4' fails while guessing
warnings.warn(f"{engine!r} fails while guessing", RuntimeWarning)
/srv/conda/envs/notebook/lib/python3.11/site-packages/xarray/backends/plugins.py:149: RuntimeWarning: 'h5netcdf' fails while guessing
warnings.warn(f"{engine!r} fails while guessing", RuntimeWarning)
/srv/conda/envs/notebook/lib/python3.11/site-packages/xarray/backends/plugins.py:149: RuntimeWarning: 'scipy' fails while guessing
warnings.warn(f"{engine!r} fails while guessing", RuntimeWarning)
display(dt_back)Radar data time-series¶
Concatenating xradar.DataTree objects along a temporal dimension is a great approach to create a more organized and comprehensive dataset. By doing so, you can maintain a cohesive dataset that is both easier to manage and more meaningful for temporal analysis.
#let's use our local files
len(local_files)5To create an ARCO dataset, we need to ensure that all radar volumes are properly aligned. To achieve this, we developed the following function:
def fix_angle(ds: xr.Dataset, tolerance: float=None, **kwargs) -> xr.Dataset:
"""
This function reindex the radar azimuth angle to make all sweeps starts and end at the same angle
@param ds: xarray dataset containing and xradar object
@param tolerance: Tolerance for interpolation between azimuth angles.
Defaul, the radar azimuth angle resolution.
@return: azimuth reindex xarray dataset
"""
ds["time"] = ds.time.load()
angle_dict = xd.util.extract_angle_parameters(ds)
start_ang = angle_dict["start_angle"]
stop_ang = angle_dict["stop_angle"]
direction = angle_dict["direction"]
ds = xd.util.remove_duplicate_rays(ds)
az = len(np.arange(start_ang, stop_ang))
ar = np.round(az / len(ds.azimuth.data), 2)
tolerance = ar if not tolerance else tolerance
ds = xd.util.reindex_angle(
ds,
start_ang,
stop_ang,
ar,
direction,
method="nearest",
tolerance=tolerance, **kwargs
)
return dsNow, we can use the Xarray.open_mfdataset method to open all nc files simultaneously. We can iterate over each sweep and concatenate them along the volume_time dimension.
# listing all the sweeps within each nc file
sweeps = [
i[1:] for i in list(dt.groups) if i.startswith("/sweep") if i not in ["/"]
]
sweeps['sweep_0',
'sweep_1',
'sweep_2',
'sweep_3',
'sweep_4',
'sweep_5',
'sweep_6',
'sweep_7',
'sweep_8',
'sweep_9',
'sweep_10',
'sweep_11',
'sweep_12',
'sweep_13',
'sweep_14',
'sweep_15',
'sweep_16',
'sweep_17',
'sweep_18',
'sweep_19']for sweep in sweeps:
root = {}
ds = xr.open_mfdataset(
local_files,
preprocess=fix_angle,
engine="cfradial1",
group=sweep,
concat_dim="volume_time",
combine="nested",
).xradar.georeference()
ds
root[f"{sweep}"] = ds
dtree = DataTree.from_dict(root)
try:
dtree.to_zarr(
"radar_ts.zarr",
consolidated=True,
)
except ContainsGroupError:
dtree.to_zarr(
"radar_ts.zarr",
consolidated=True,
mode="a",
)
del dtree, dsLet’s see our new radar-time series dataset
dtree = xr.backends.api.open_datatree(
"radar_ts.zarr",
consolidated=True,
chunks={}
)/srv/conda/envs/notebook/lib/python3.11/site-packages/xarray/backends/plugins.py:149: RuntimeWarning: 'netcdf4' fails while guessing
warnings.warn(f"{engine!r} fails while guessing", RuntimeWarning)
/srv/conda/envs/notebook/lib/python3.11/site-packages/xarray/backends/plugins.py:149: RuntimeWarning: 'h5netcdf' fails while guessing
warnings.warn(f"{engine!r} fails while guessing", RuntimeWarning)
/srv/conda/envs/notebook/lib/python3.11/site-packages/xarray/backends/plugins.py:149: RuntimeWarning: 'scipy' fails while guessing
warnings.warn(f"{engine!r} fails while guessing", RuntimeWarning)
dtreeWe have successfully created a Analysis-Ready Cloud-Optimezed dataset.
Summary¶
We discussed the concept of Analysis-Ready Cloud-Optimezed (ARCO) datasets, emphasizing the importance of datasets that are pre-processed, clean, and well-organized. Leveraging the Climate and Forecast (CF) format-based FM301 hierarchical tree structure, endorsed by the World Meteorological Organization (WMO), we developed an open data model to arrange, manage, and store radar data in cloud-storage buckets efficiently. The ultimate goal of radar ARCO data is to streamline the data science process, making datasets immediately usable without the need for extensive preprocessing.
What’s next?¶
Now, we can explore some quantitavite precipitation estimation (QPE) and quasy-vertical profiles (QVP) demos in the QPE-QVPs notebook.